Презентация - Между языком и компьютером
Нужно больше вариантов? Смотреть похожие Нажмите для полного просмотра 
|
Распечатать
- Уникальность: 91%
- Слайдов: 38
- Просмотров: 3356
- Скачиваний: 1467
- Размер: 49.65 MB
- Онлайн: Да
- Формат: ppt / pptx
Примеры похожих презентаций
 Передача информации между компьютером. Проводная и беспроводная связь
Передача информации между компьютером. Проводная и беспроводная связь Школа как производитель - Школа купила компьютер
Школа как производитель - Школа купила компьютер Влияние компьютера на психику детей
Влияние компьютера на психику детей Фракталы. В компьютерной графике
Фракталы. В компьютерной графике Компьютерная игра «Жизнь». Информационный проект
Компьютерная игра «Жизнь». Информационный проект Построение и исследование графиков функций с использованием программного обеспечения компьютеров
Построение и исследование графиков функций с использованием программного обеспечения компьютеров Компьютерный стол в реальном и виртуальном мире
Компьютерный стол в реальном и виртуальном мире
Слайд 1

Между языком и компьютером Малый филологический факультет 17.10.2019
Слайд 2

Что такое корпус? Национальный корпус представляет данный язык на определенном этапе (или этапах) его существования и во всём многообразии жанров, стилей, территориальных и социальных вариантов и т. п. НКРЯ ? Сorpus - Corp ora Корпус - К ó рпусы / корпус á информационно-справочная система, основанная на собрании текстов на некотором языке в электронной форме
Слайд 3

А Зачем?.. Лингвистические задачи от карточки к корпусу (если он есть, конечно ) Литературоведческие задачи Авторский язык vs. язык эпохи Автор 1 vs. Автор 2,3,4 Автор 1 vs. Автор 1: в синхронии и диахронии Прикладные задачи Информационный поиск, извлечение фактов, SEO-анализ, проверка на плагиат, юридическая лингвистика, чат-боты
Слайд 4

Ключевые слова ВХОЖДЕНИЕ количество единиц, соответствующих запросу ЛЕММА начальная форма слова СЛОВОФОРМА одна из косвенных форм слова ТОКЕН единица измерения корпусов (слово от пробела до пробела) ТИП количество разных лемм/словоформ IPM (item per million) частота слова на миллион: число вхождений 100 000/общее кол-во слов ОМОНИМИЯ отношения лексических единиц,
совпадающих по форме и не связанных по значению
Слайд 5

Выражения для поиска
(главным образом для нкря) любая последовательность знаков и & не – или
Слайд 6

Какие бывают корпуса? письменный устный параллельный детской речи корпус ошибок медиакорпус литературоведческие обучающий РАЗНЫЕ!
Слайд 7
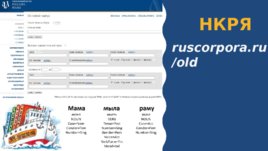
НКРЯ
Слайд 8
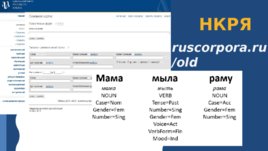
НКРЯ
Слайд 9

Český národní korpus Параметры доступа: свободный, но с регистрацией больше возможностей 1994 – создание Института Чешского национального корпуса при Факультете философии Карлова университета
Слайд 10
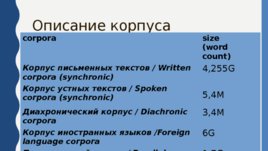
Описание корпуса corpora size (word count) Корпус письменных текстов / Written corpora (synchronic) 4,255G Корпус устных текстов / Spoken corpora (synchronic) 5,4М Диахронический корпус / Diachronic corpora 3,4М Корпус иностранных языков /Foreign language corpora 6G Параллельный корпус / Parallel corpus 1,7G
Слайд 11
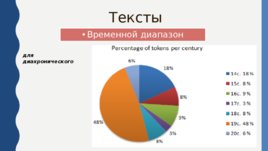
Тексты Временной диапазон для диахронического
Слайд 12
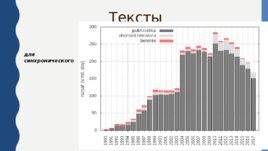
Тексты для синхронического
Слайд 13

Возможности интерфейса User-friendly Лемматизация Удобный вывод информации о частоте (в т.ч. в диахронии), употребляемости в текстах разных жанров Автоматическое создание wordcloud с словоформами Коллокации Отслеживание социологических факторов (гендер, образование, возраст) Географическое распределение употребления слова Примеры употребления в живой речи WORD AT GLANCE
Слайд 14
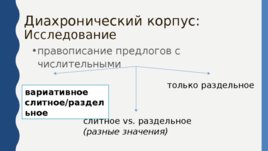
Диахронический корпус:
Исследование правописание предлогов с числительными вариативное слитное/раздельное слитное vs. раздельное (разные значения) только раздельное
Слайд 15

Тенденция к слитному или раздельному написанию?
Слайд 16

CLi C –
Dickens Корпусные методы как новые инструменты изучения литературы и читательского восприятия текста. CLi C Dickens является результатом сотрудничества University of Nottingham (2013) и University of Birmingham. Более 130 книг. Доступные корпуса: Dickens s Novels (DNov), 19th Century Reference Corpus (19C), 19th Century Children s Literature (Chi Lit), Additional Requested Texts (Ar Ts). (Corpus Linguistics in Context)
Слайд 17

Гикря webcorpora.ru 19801 млн слов, 279903439 документов Закрытый доступ Социолингвистические данные Live Journal, Вконтакте
Слайд 18

Dracor shiny.dracor.org НИУ ВШЭ и Потсдамский университет Корпус драматических текстов Rus Dra Cor (80 пьес), Ger Dra Cor (465 пьесы) Периодизация: середина XVIII – первая половина XX века Wikisource (wikisource.org), the Русская виртуальная библиотека (rvb.ru), Интернет-библиотека Алексея Комарова (ilibrary.ru) and Библиотека Максима Мошкова (lib.ru)
Слайд 19

Все Связано: Сети социальных взаимодействий Количественные и структурные исследования русской драмы: определяем «влиятельность» литературного героя и не только Определение социальной сети: кто с кем разговаривает? В каждом акте, сцене и т.д. Анализ связей между действующими лицами (акторами) с помощью графа
Слайд 20

Граф, его вершины и ребра Граф – способ формально описать взаимосвязи между набором элементов (вершин) Два основных понятия: вершины (узлы, vertices , nodes) и связи (дуги, ребра, links, edges ) Ребро (edge) – связь между элементами, представляется как пара вершин (начало-конец) Ориентированный граф – несимметричная связь, направление важно Неориентированный граф – симметричная связь ( A и B связаны)
Слайд 21
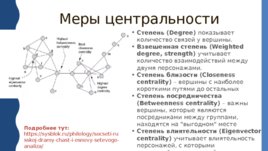
Меры центральности Степень (Degree) показывает количество связей у вершины. Взвешенная степень (Weighted degree, strength) учитывает количество взаимодействий между двумя персонажами. Степень близости (Closeness centrality) – вершины с наиболее короткими путями до остальных Степень посредничества (Betweenness centrality) – важны вершины, которые являются посредниками между группами, находятся на "выгодном" месте Степень влиятельности (Eigenvector centrality) учитывает влиятельность персонажей, с которыми взаимодействует данный персонаж (главные/второстепенные) Подробнее тут:
Слайд 22

Между языком и компьютером Малый филологический факультет семинар
Слайд 23
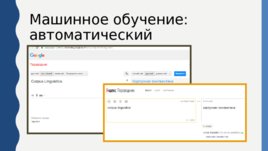
Машинное обучение: автоматический перевод
Слайд 24

Параллельный корпус/
переводоведческие корпуса Конкордансеры (Concordancers) – списки контекстов Computer-assisted translation (CAT) – «память/накопитель переводов» (Translation Memory databases) Электронные словари
Слайд 25

Чат-боты
(Виртуальные собеседники)
Слайд 26

Первый чат-бот Элиза Элиза (ELIZA) — виртуальный собеседник, знаменитая компьютерная программа Джозефа Вейценбаума, написанная им в 1966 году, которая пародирует диалог с психотерапевтом, реализуя технику активного слушания Wiki
Слайд 27

Алиса от
Слайд 28

Azuma Hikari
Слайд 29
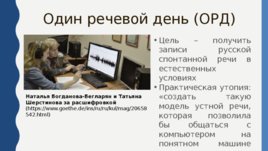
Один речевой день (ОРД) Цель – получить записи русской спонтанной речи в естественных условиях Практическая утопия: «создать такую модель устной речи, которая позволила бы общаться с компьютером на понятном машине языке» Наталья Богданова-Бегларян и Татьяна Шерстинова за расшифровкой ()
Слайд 30

128 информантов
мужчины и женщины
(возраст 17 - 80)
более 1000 собеседников
(возраст 3 - 85) (более 1400 часов звучания) Шерстинова 2018
Слайд 31

динамика эпизодов речевого дня Шерстинова 2018 Шерстинова 2008
Слайд 32

Обработка записи О начальных этапах проекта:
Слайд 33

Устные корпуса / Рассказы о сновидениях Корпус состоит из 129 рассказов детей и подростков от 7 до 17 лет об увиденном ими во сне. Рассказы записывались непосредственно после пробуждения. Общая длительность звучания — около 2 часов; объем корпуса — около 14 тысяч словоупотреблений. Рассказы разбиты на две группы: 60 рассказов взяты от детей и подростков из контрольной группы, 69 рассказов — от участников эксперимента с теми или иными невротическими расстройствами. Джон Анстер Фицжеральд «Сновидения»
Слайд 34

ЗАДАНИЕ Составьте рассказ по картинке Есть такой корпус!
Слайд 35
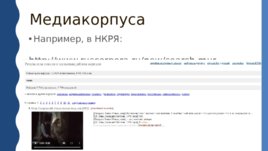
Медиакорпуса Например, в НКРЯ:
Слайд 36

Корпуса детской речи Например, детская речь на русском языке в CHILDES:
Слайд 37
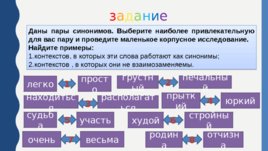
з а д а н и е Даны пары синонимов. Выберите наиболее привлекательную для вас пару и проведите маленькое корпусное исследование. Найдите примеры: контекстов, в которых эти слова работают как синонимы; контекстов , в которых они не взаимозаменяемы. находиться располагаться 3 худой стройный 6 родина отчизна 8 судьба участь 5 очень весьма 7 прыткий юркий 4 легко просто 1 грустный печальный 2
Слайд 38

Спасибо!
^ Наверх
X
Благодарим за оценку!
Мы будем признательны, если Вы так же поделитесь этой презентацией со своими друзьями и подписчиками.